In this in-depth tutorial, the author explores how an HTTP server works at the byte level, from raw TCP sockets to request parsing, routing, MIME types, and gzip compression. Through clear explanations and focused code examples drawn from building a server from scratch in Python, the article is ideal for developers who want to understand how the web works beneath frameworks.
Why I Built My Own HTTP Server
When I started backend development, I felt that if I jumped straight into frameworks, I would be building on top of something I did not truly understand. And with AI able to scaffold projects and generate boilerplate in seconds, slowing down to learn the fundamentals felt more important than ever.
So, I built an HTTP server from scratch in Python.
I wanted to see what really happens between a client and a server, to understand HTTP at the level where everything is just bytes and structure. Once I began reading raw bytes from a browser, the “magic” disappeared and HTTP revealed itself as a simple, disciplined dialogue between two machines.
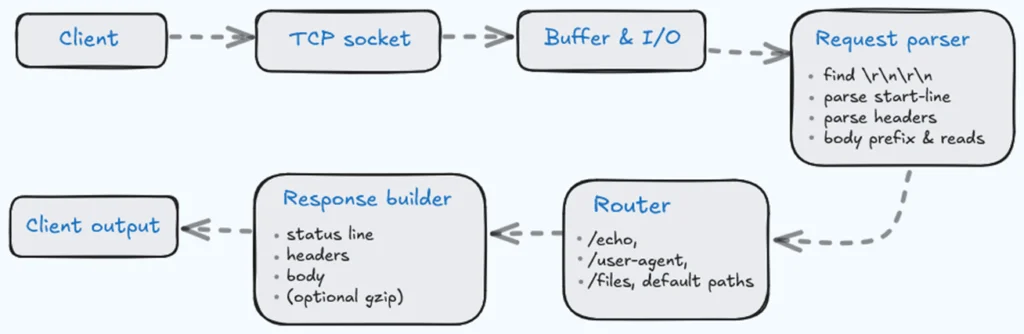
You can find the full implementation and commits on my GitHub repo. To make the flow easier to visualize, here is the end-to-end path a request follows inside the server, each stage adding just enough structure to turn a byte stream into a valid HTTP response.
The Bare Metal: TCP Sockets
Every HTTP server begins by creating a TCP socket. TCP, which stands for Transmission Control Protocol, provides a continuous stream of bytes between two machines. The server binds this socket to an address and listens for incoming connections. The moment a client connects, you receive a stream of bytes, and that stream is your only source of truth.
Python snippet
def serve_forever(self) -> NoReturn:
sem = threading.Semaphore(self.config.max_concurrent_connections)
lock = threading.Lock()
server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEPORT, 1)
server_socket.bind((self.config.host, self.config.port))
server_socket.listen(64)In the code above, the server sets up that listening socket. It creates a semaphore to cap the number of concurrent connections, a lock to protect shared state, and then a TCP socket using AF_INET and SOCK_STREAM. The socket option SO_REUSEPORT is enabled so the server can restart cleanly on the same port, after which the socket is bound to the configured host and port and put into listening mode, ready to accept incoming clients.
This is the first real lesson: TCP does not care about message boundaries. You might receive half a request, one and a half requests, headers in one chunk and the body in another, or everything mixed together. It’s your job to impose structure on that chaos. Working at this layer forces a new mindset: thinking in terms of buffering, partial reads, and unpredictable arrival patterns. Before I even touched HTTP, the socket taught me to treat incoming data as unstructured and indifferent to my expectations.
Parsing the request: finding structure in the chaos
Once bytes arrive, the next challenge is deciding where the HTTP request ends. HTTP gives you two essential landmarks:
\r\n\r\n: the separator (carriage return line feed – CRLF) between headers and bodyContent-Length: how many bytes belong to the body
To turn the raw header bytes into a structured request, the server does three things:
- Decode the incoming bytes so it can search for
\r\n\r\nand split text lines safely, even if the client sends odd characters. - Extract the start-line by splitting at the first
\r\n. If that separator is not found, the request is malformed because HTTP requires a start-line followed by headers. - Validate the start-line format by splitting it on spaces. A proper request line must have exactly three parts:
<method> <request-target> <http-version>.
Python snippet
text = header_bytes.decode("utf-8", errors="replace")
try:
start_line, header_block = text.split(CRLF, 1)
except ValueError:
raise BadRequest("Malformed request: missing CRLF after the start-line")
parts = start_line.split(" ")
if len(parts) != 3:
raise BadRequest("A request line must follow: "
"<method>SPACE<request-target>SPACE<HTTP-version>CRLF")
method, target, http_version = parts[0], parts[1], parts[2]In the code above, the server decodes the raw header bytes into text, then tries to split once on the first CRLF to separate the start-line from the rest of the header block. If this split fails, it raises a BadRequest error because a valid HTTP request must begin with a start-line. It then splits the start-line on spaces and checks that there are exactly three parts; otherwise, it raises another BadRequest explaining the required format. Finally, it assigns those three parts to method, target, and http_version, turning an unstructured line of text into a clean, typed request line. Once the header section is isolated, the server can parse the remaining headers and determine whether a body is expected.
Handling real-world byte streams
Clients rarely send data in perfectly shaped segments. A header block might be split across reads, or arrive glued together with the first part of the body. To handle this, the server uses a simple loop:
- Read the socket in chunks and append each chunk to a growing buffer.
- Stop as soon as
\r\n\r\nappears; at that point, the headers are complete. Reject oversized or stalled requests via limits and timeouts. - Split the buffer into two parts:
-
body_prefix: any bytes that arrived after the headers (often the first slice of the request body) -
header_bytes: everything up to and including\r\n\r\n
-
Python snippet
while True:
chunk = conn.recv(4096)
if not chunk:
break
buffer += chunk
if end in buffer:
break
if len(buffer) > max_headers:
raise BadRequest("Header section too large.")
if end not in buffer:
raise BadRequest("Header section incomplete.")
head_end = buffer.index(end) + len(end)
header_bytes = bytes(buffer[:head_end])
body_prefix = bytes(buffer[head_end:])
return header_bytes, body_prefixIn the snippet above, the server repeatedly calls recv(4096) and appends each chunk to buffer. As soon as the header terminator sequence is found, the loop breaks. If the buffer grows beyond max_headers, it raises BadRequest("Header section too large.") to protect the server from oversized or malicious requests. After the loop, it checks that the terminator is actually present; if not, it raises BadRequest("Header section incomplete."). Finally, it computes the position of the header end, slices out header_bytes and body_prefix, and returns both so later code can continue parsing.
Now the server needs to read the request body. It does this by using Content-Length to finish the job:
- Check how many bytes the client promised to send using
Content-Length. - Reject oversized bodies early using a configured maximum size.
- Start the body buffer using the prefix already received.
- Continue reading from the socket until the body length matches
Content-Length. - If the connection closes before all bytes arrive, the server raises an error for an incomplete body.
Python snippet
total = req.content_length or 0
if total == 0:
req.add_body(b"")
return
if total > self.config.max_body_bytes:
raise PayloadTooLarge()
body = bytearray(req.body_prefix)
if len(body) > total:
body = body[:total]
while len(body) < total:
chunk = conn.recv(min(4096, total - len(body)))
if not chunk:
raise IncompleteBody()
body += chunkIn this second snippet, the server does exactly that. It looks at req.content_length to determine how many bytes it should expect. If the total is zero, it simply attaches an empty body and returns. If the total exceeds max_body_bytes, it raises PayloadTooLarge. It then initializes body from the previously captured body_prefix. If that prefix already contains more bytes than expected, it trims it down to exactly total. Otherwise, it keeps calling recv() until len(body) reaches total, and if the connection closes too early it raises IncompleteBody. This guarantees that the final body matches the declared Content-Length exactly. This approach works even when clients pipeline multiple requests or send headers and body together, because the server trusts boundaries, not timing. Parsing HTTP manually forces precision and reveals why real servers care so much about buffering and strict message framing.
Routing, file serving and HTTP response
Once the request is parsed, the server decides how to respond. Every HTTP response follows a strict skeleton: a status line, a series of HTTP headers, and usually a message body. If any part is malformed, especially Content-Length, the browser rejects it.
Example: the /user-agent endpoint
This is a simple dynamic route that illustrates the basics:
- Read the
User-Agentheader from the parsed request. - Use it as the plain-text body.
- Build a response with
200 OK,Content-Type: text/plain, and the correctContent-Length. - Send headers and body together with correct CRLF formatting.
Python snippet
elif path == "/user-agent":
ua = req.get_header("user-agent")
body = ua.encode("utf-8")
head = CRLF.join([
HTTP_CODE_200,
"Content-Type: text/plain",
f"Content-Length: {len(body)}",
"Connection: close",
]) + END_HEADERS
return head.encode('utf-8') + bodyIn the snippet above, when the path equals /user-agent, the server pulls the User-Agent header from the request, encodes it as bytes, and uses that as the response body. It then assembles the response head by joining the status line and headers (Content-Type, Content-Length, Connection) with CRLF, appends the final blank line, and returns the encoded headers followed by the body bytes. This is a minimal but complete example of constructing a valid HTTP response by hand.
Even tiny mistakes here break clients, which made response construction feel surprisingly exacting.
Example: the /files/ endpoint
The /files/ endpoint turns the server into a small static file server with safety checks:
- Validate the filename (rejecting
..and unsafe path escapes). - Resolve it against a fixed root directory.
- Return
404if the file is outside the root or does not exist. - For
GET, read the file’s bytes and return them withContent-Type: application/octet-stream. - For
POST, write the request body into a file and return201 Created.
In the code snippets below, you can see these safeguards in action.
Extracting and validating the filename
The server first checks whether the path starts with /files/ and uses partition to extract the requested filename. If the filename is empty or contains / or .., the server immediately returns 404, blocking directory-traversal attempts.
Python snippet
elif path.startswith("/files/"):
_, _, filename = path.partition("/files/")
if not filename or "/" in filename or ".." in filename:
head = HTTP_CODE_404 + END_HEADERS
return head.encode("utf-8")Resolving the path safely
Once the filename passes the initial validation, the server resolves it against a fixed root directory. Using relative_to, it verifies that the resolved path is still inside that root. If the resolution escapes the allowed directory, the server logs a message and rejects the request with 404.
Python snippet
else:
full_root = file_root.resolve()
full_path = (full_root / filename).resolve()
try:
full_path.relative_to(full_root)
except ValueError:
print(f"Cannot read '{filename}' "
"as it is outside the permitted directory.")
head = HTTP_CODE_404 + END_HEADERS
return head.encode("utf-8")Handling GET requests
If the request method is GET, the server checks whether the resolved path points to a real file. If not, it returns 404. Otherwise, it reads the file’s bytes, constructs a 200 OK response with Content-Type: application/octet-stream and an accurate Content-Length, and sends the headers followed by the file content.
Python snippet
if req.method == 'GET':
if not full_path.is_file():
print(f"'{filename}' is not a file or format not allowed.")
head = HTTP_CODE_404 + END_HEADERS
return head.encode("utf-8")
try:
content = full_path.read_bytes()
head = CRLF.join([
HTTP_CODE_200,
"Content-Type: application/octet-stream",
f"Content-Length: {len(content)}",
"Connection: close",
]) + END_HEADERS
return head.encode('utf-8') + contentHandling POST requests
For POST requests, the server delegates the write operation to a helper function that writes the body to disk and verifies the result. If the write succeeds, the handler returns 201 Created; otherwise, it logs the error and returns a failure response.
Python snippet
if req.method == 'POST':
if create_write_file(full_path, req):
head = HTTP_CODE_201 + END_HEADERS
return head.encode('utf-8')MIME types in practice
At this point, MIME types start to matter. To the server, everything is just bytes; the browser needs labels. The Content-Type header tells the browser whether the data is HTML, JSON, an image, or something else. It’s a small detail, but essential to client behavior:
text/plain→ raw texttext/html→ HTML documentapplication/json→ JSON dataapplication/octet-stream→ arbitrary binary fileimage/png→ PNG imageimage/jpeg→ JPEG image
Gzip compression: transforming content the right way
To support gzip, the server checks the Accept-Encoding header. If gzip is not listed, it returns the original body unchanged. If it is supported, the server:
- compresses the body,
- adds
Content-Encoding: gzip, - recalculates
Content-Lengthto match the compressed size.
Python snippet
if "accept-encoding" in req.headers:
comp_scheme = req.get_header("accept-encoding")
if "gzip" not in comp_scheme:
head = CRLF.join([
HTTP_CODE_200,
"Content-Type: text/plain",
f"Content-Length: {len(body)}",
"Connection: close",
]) + END_HEADERS
return head.encode("utf-8") + body
else:
compressed_body = gzip.compress(body)
head = CRLF.join([
HTTP_CODE_200,
"Content-Type: text/plain",
"Content-Encoding: gzip",
f"Content-Length: {len(compressed_body)}",
"Connection: close",
]) + END_HEADERS
return head.encode("utf-8") + compressed_bodyAs shown in the code above, the server retrieves the Accept-Encoding header and checks whether it contains the string "gzip". If not, it builds a normal 200 OK response with the uncompressed body. If gzip is allowed, the server compresses the response body using gzip.compress(), sets Content-Encoding: gzip, and computes the new Content-Length based on the compressed bytes before sending the response.
This is where message framing becomes unavoidable. After compression, the server must send exactly the number of bytes it declares. One extra or missing byte leads to a corrupted stream or a hanging browser.
Beyond correctness, gzip shows why the modern web feels fast. Human-readable data compresses extremely well, cutting bandwidth and latency. Clients expect gzip almost automatically, because compression is now a standard part of web performance. Implementing it gave me a practical understanding of why servers care so much about precision and efficiency.
Pitfalls that only show up when you build it yourself
Working through these features exposed the problems that frameworks normally shield you from. Buffering and partial reads became constant companions: a single recv() might contain half a header, two headers glued together, or a body split across multiple fragments.
Another challenge was handling more than one request on the same connection. Even without full keep-alive support, a single read could contain the end of one request and the beginning of the next. Reading even one byte too far meant accidentally swallowing part of the next message.
Then there was the inevitable off-by-one Content-Length bug. If the length I advertised did not match the actual body, even by a single byte, the browser would discard the response or hang indefinitely.
Gzip came with its own sharp edges as well: one wrong size, one incorrect frame, and the browser simply refused to decode the stream. These small battles are where HTTP stops being a neat list of rules and becomes something you can feel. TCP is not trying to help you; it simply delivers whatever arrives. In those unpredictable corners, real intuition is built. No framework or tutorial can give you that.
Where a custom HTTP server makes sense
I built this server as a learning exercise, but it also made me notice where a tiny hand-rolled server genuinely has value.
Some environments need something light and predictable, especially embedded or constrained systems where a full framework is excessive. In other contexts, you may need complete control over the bytes on the wire: for experimenting with protocol behavior or testing edge cases that mainstream servers hide.
There are long-lived systems built on older or proprietary protocols that expect very specific communication patterns. In those cases, building your own server is not over-engineering; it is the only way to meet the requirements.
And for debugging, a minimal server that shows exactly what it sends and receives is incredibly useful for performance investigations and networking issues, where removing abstraction brings clarity. I did not begin this project thinking about real-world uses, but working this close to the protocol made those possibilities hard to miss.
Next step: persistent connections
With the basics and gzip in place, my next step is implementing persistent connections.
HTTP/1.1 encourages reusing the same connection for multiple requests, which means:
- reading the next request without mixing it with leftover bytes,
- avoiding reads that block forever,
- keeping clean state across consecutive messages.
At that point, it starts feeling less like a single exchange and more like a conversation streamed over time.
Why fundamentals matter even more in the AI era
Building this server changed how I see backend development. AI can write code, scaffold apps, and fill in patterns, but it cannot give you intuition. It cannot teach you why something breaks or help you debug a system that behaves unexpectedly.
The fundamentals — buffering, framing, parsing, MIME types, compression — are the bedrock beneath everything else. The more we automate, the more these foundations matter. Building an HTTP server was not about reinventing anything. It was about grounding myself before climbing higher.
Subscribe to our newsletter!









+ There are no comments
Add yours